| 深度学习 | 您所在的位置:网站首页 › 图像分类算法 神经网络模型有哪些 › 深度学习 |
深度学习
|
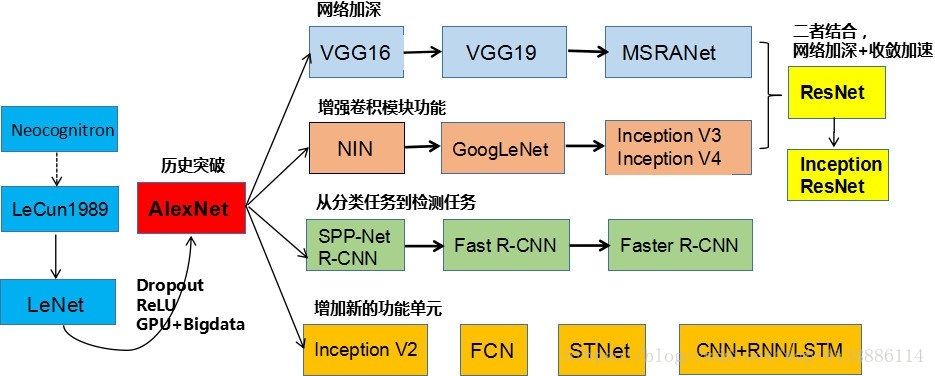
一、 CNN结构演化历史的图二、 AlexNet网络
2.1 ReLU 非线性激活函数
多GPU训练(Training on Multiple GPUs)局部响应归一化(Local Response Normalization)重叠池化(Overlapping Pooling) 2.2 降低过拟合( Reducing Overfitting)
数据增强(Data Augmentation)Dropout 三、VGG网络
VGG 网络 卷积层组合 详解 四、GoogleLeNet网络
Inception V1网络(NIN结构)Inception V2、V3、V4 五、ResNet 网络
原文地址:https://blog.csdn.net/wsp_1138886114/article/details/81386422#三vgg网络 欢迎来到我得主页:https://blog.csdn.net/Sakura55/article/details/80678611 一、 CNN结构演化历史的图Deep Learning模型大名鼎鼎的AlexNet模型 大量数据,Deep Learning领域应该感谢李飞飞团队搞出来如此大的标注数据集合ImageNet;GPU,这种高度并行的计算神器确实助了洪荒之力,没有神器在手,Alex估计不敢搞太复杂的模型;算法的改进,包括网络变深、数据增强、ReLU、Dropout等使用梯度下降法的多层网络可以从大量的数据中学习复杂的,高纬,非线性的映射,这使得他们成为图像识别任务的首选。 全连接的多层网络可以作为分类器。 首先,图像是非常大的,由很多像素组成。具有100个隐藏单元的全连接网络包含成千上万的权重。为了解决系统的消耗和内存占用问题,在下面描述的卷积神经网络中,位移不变性(shift invariance)可以通过权值共享实现。 全连接的网络的另一个缺点就是完全忽略了输入的拓扑结构。在不影响训练的结果的情况下,输入图像可以是任意的顺序。CNN通过将隐藏结点的感受野限制在局部来提取特征。 CNN通过局部感受野(local receptive fields),权值共享(shared weights),下采样(sub-sampling)实现位移,缩放,和形变的不变性(shift,scale,distortion invariance)。 卷积层的核就是特征图中所有单元使用的一组连接权重。卷积层的一个重要特性是如果输入图像发生了位移,特征图会发生相应的位移,否则特征图保持不变。这个特性是CNN对位移和形变保持鲁棒的基础。 一旦计算出feature map,那么精确的位置就变得不重要了,相对于其他特征的大概位置是才是相关的。 在特征图中降低特征位置的精度的方式是降低特征图的空间分辨率,这个可以通过下采样层达到,下采样层通过求局部平均降低特征图的分辨率,并且降低了输出对平移和形变的敏感度。 2.1 ReLU 非线性激活函数
第一层卷积层使用96个大小为11x11x3的卷积核对224x224x3的输入图像以4个像素为步长(这是核特征图中相邻神经元感受域中心之间的距离)进行滤波。 第二层卷积层将第一层卷积层的输出(经过响应归一化和池化)作为输入,并使用256个大小为5x5x48的核对它进行滤波。 第三层、第四层和第五层的卷积层在没有任何池化或者归一化层介于其中的情况下相互连接。 第三层卷积层有384个大小为3x3x256的核与第二层卷积层的输出(已归一化和池化)相连。 第四层卷积层有384个大小为3x3x192的核,第五层卷积层有256个大小为 的核。每个全连接层有4096个神经元。 方法1:生成平移图像和水平翻转图像。做法就是从256x256的图像中提取随机的224x224大小的块(以及它们的水平翻转),然后基于这些提取的块训练网络。softmax层对这十个块做出的预测取均值。 方法2:改变训练图像的RGB通道的强度。特别的,本文对整个ImageNet训练集的RGB像素值进行了PCA。对每一幅训练图像,本文加上多倍的主成分,倍数的值为相应的特征值乘以一个均值为0标准差为0.1的高斯函数产生的随机变量。 Dropout 它将每一个隐藏神经元的输出以50%的概率设为0。这些以这种方式被“踢出”的神经元不会参加前向传递,也不会加入反向传播。因此每次有输入时,神经网络采样一个不同的结构,但是所有这些结构都共享权值。这个技术降低了神经元之间复杂的联合适应性。 Dropout方法和数据增强一样,都是防止过拟合的。Dropout应该算是AlexNet中一个很大的创新 三、VGG网络VGG 网络是由conv、pool、fc、softmax层组成。VGG网络的卷积层,没有缩小图片,每层pad都是有值的,图片缩小都是由pool来实现的。 网络包含了16个卷积/全连接层。网络的结构非常一致,从头到尾全部使用的是3x3的卷积和2x2的汇聚。 他们的预训练模型是可以在网络上获得并在Caffe中使用的。VGGNet不好的一点是它耗费更多计算资源,并且使用了更多的参数,导致更多的内存占用(140M)。 其中绝大多数的参数都是来自于第一个全连接层。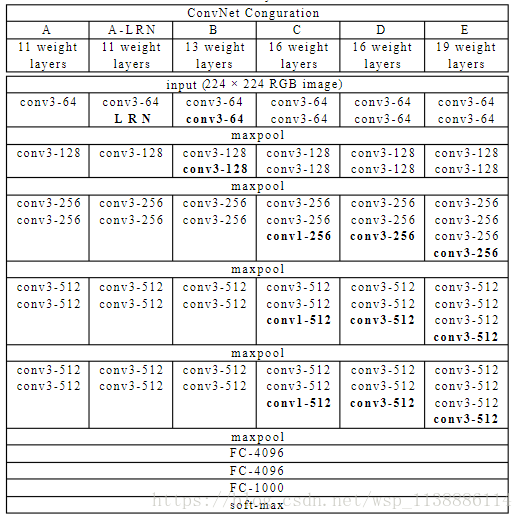 VGG 网络 卷积层组合 详解
首先,多个卷积层与非线性的激活层交替的结构,比单一卷积层的结构更能提取出深层的更好的特征。 其次,假设所有的数据有C个通道,那么单独的7x7卷积层将会包含7*7*C=49C2个参数; 而3个3x3的卷积层的组合仅有个3*(3*3*C)=27C2个参数。 小滤波器的卷积层组合,可以表达出输入数据中更多个强力特征,使用的参数也更少 。唯一的不足是,在进行反向传播时,中间的卷积层可能会导致占用更多的内存。
四、GoogleLeNet网络
VGG 网络 卷积层组合 详解
首先,多个卷积层与非线性的激活层交替的结构,比单一卷积层的结构更能提取出深层的更好的特征。 其次,假设所有的数据有C个通道,那么单独的7x7卷积层将会包含7*7*C=49C2个参数; 而3个3x3的卷积层的组合仅有个3*(3*3*C)=27C2个参数。 小滤波器的卷积层组合,可以表达出输入数据中更多个强力特征,使用的参数也更少 。唯一的不足是,在进行反向传播时,中间的卷积层可能会导致占用更多的内存。
四、GoogleLeNet网络
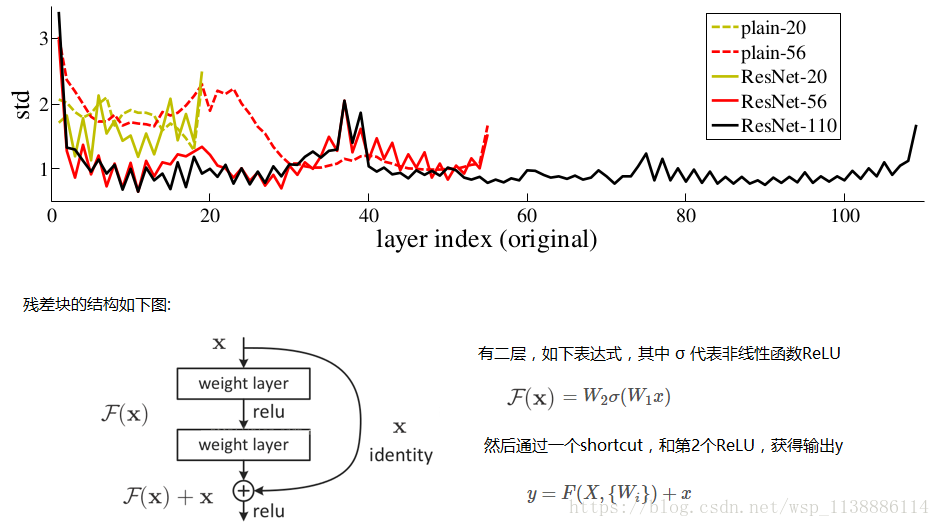
借鉴了Highway Network思想的网络 (残差网络) 在2015名声大噪,而且影响了2016年DL在学术界和工业界的发展方向。 该相当于旁边专门开个通道使得输入可以直达输出,而优化的目标由原来的拟合输出H(x)变成输出和输入的差H(x)-x,其中H(X)是某一层原始的的期望映射输出,x是输入。 
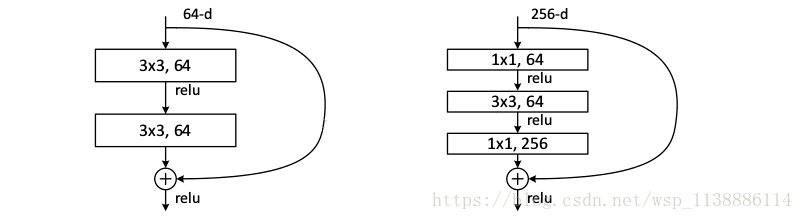
它对每层的输入做一个reference, 学习形成残差函数, 而不是学习一些没有reference的函数。这种残差函数更容易优化,能使网络层数大大加深。 ResNet学习的是残差函数F(x) = H(x) - x, 这里如果F(x) = 0, 那么就是上面提到的恒等映射。 事实上,resnet是“shortcut connections”的在connections是在恒等映射下的特殊情况,它没有引入额外的参数和计算复杂度。 假如优化目标函数是逼近一个恒等映射, 而不是0映射, 那么学习找到对恒等映射的扰动会比重新学习一个映射函数要容易。 从图可以看出,残差函数一般会有较小的响应波动,表明恒等映射是一个合理的预处理。 实验证明,这个残差块往往需要两层以上,单单一层的残差块(y=W1x+x)并不能起到提升作用。 考虑计算的成本,对残差块做了计算优化,即将两个3x3的卷积层替换为1x1 + 3x3 + 1x1, 如下图。 新结构中的中间3x3的卷积层首先在一个降维1x1卷积层下减少了计算,然后在另一个1x1的卷积层下做了还原,既保持了精度又减少了计算量。 鸣谢 https://blog.csdn.net/mao_feng/article/details/52734438 https://www.cnblogs.com/52machinelearning/p/5821591.html 文献: Gradient-Based Learning Applied to Document Recognition ImageNet Classification with Deep Convolutional Neural Networks |
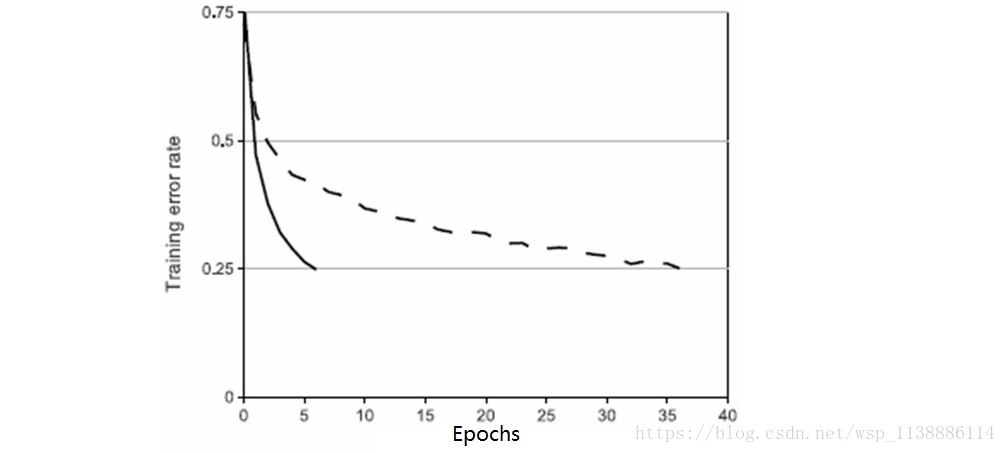 通常这种标准函数是 f(x)=tanh(x)f(x)=tanh(x) 。在梯度下降训练时间上,这些饱和的非线性函数比不饱和非线性函数f(x)=max(0,x)更慢。下图这种非线性特征的神经元称为修正线性单元(ReLUs: Rectified Linear Units)。使用ReLUs的深度卷积神经网络训练速度比同样情况下使用tanh单元的速度快好几倍。 ReLUs主要是对训练集的拟合进行加速。快速学习对由大规模数据集上训练出大模型的性能有相当大的影响。
通常这种标准函数是 f(x)=tanh(x)f(x)=tanh(x) 。在梯度下降训练时间上,这些饱和的非线性函数比不饱和非线性函数f(x)=max(0,x)更慢。下图这种非线性特征的神经元称为修正线性单元(ReLUs: Rectified Linear Units)。使用ReLUs的深度卷积神经网络训练速度比同样情况下使用tanh单元的速度快好几倍。 ReLUs主要是对训练集的拟合进行加速。快速学习对由大规模数据集上训练出大模型的性能有相当大的影响。 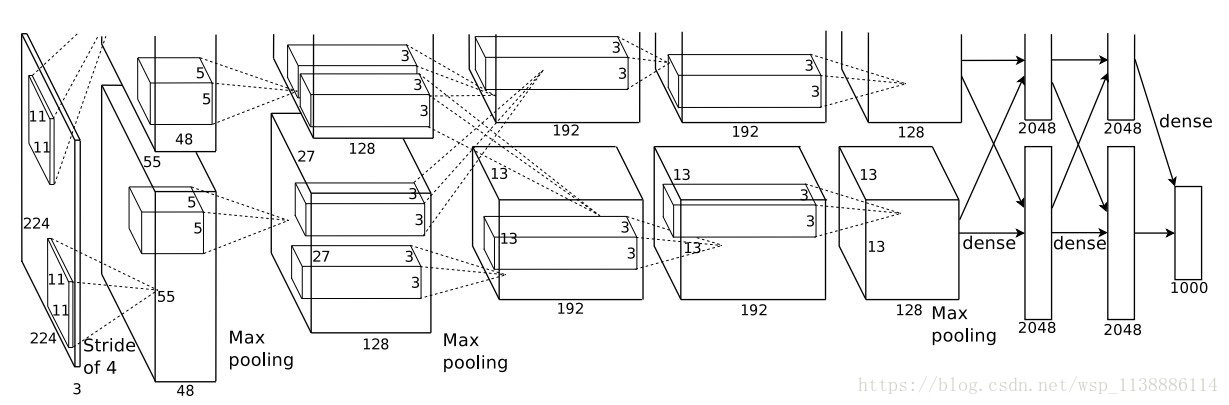 图2 本文CNN的结构图示,明确地描述了两个GPU之间的职责。一个GPU运行图上方的层,另一个运行图下方的层。两个GPU只在特定的层通信。网络的输入是150,528维的,网络剩余层中的神经元数目分别是253440,186624,64896,64896,43264,4096,4096,1000
图2 本文CNN的结构图示,明确地描述了两个GPU之间的职责。一个GPU运行图上方的层,另一个运行图下方的层。两个GPU只在特定的层通信。网络的输入是150,528维的,网络剩余层中的神经元数目分别是253440,186624,64896,64896,43264,4096,4096,1000 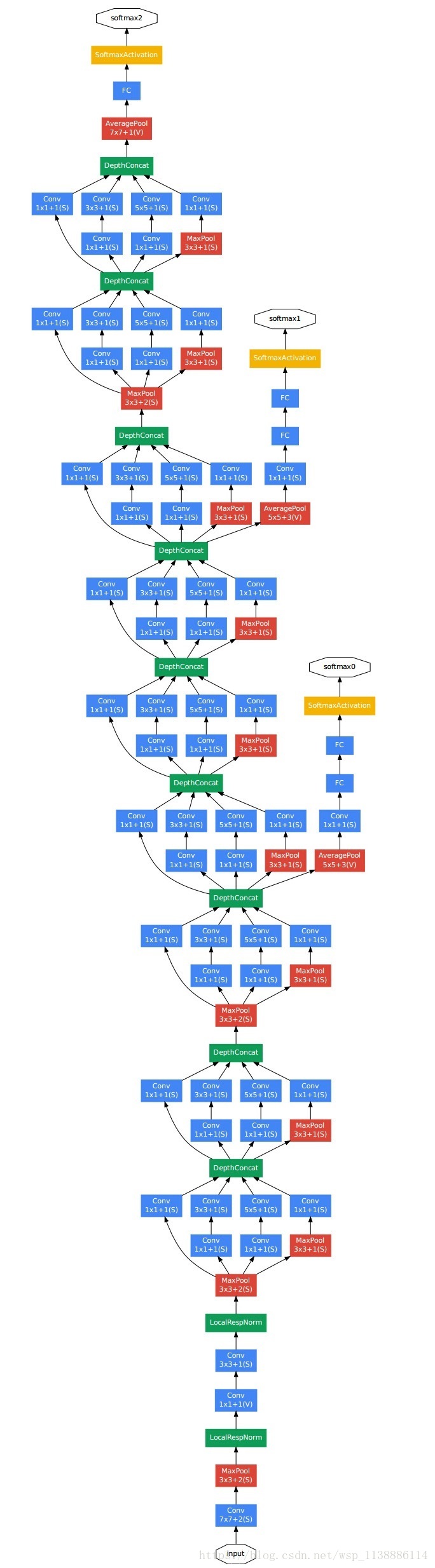
【本文地址】